Tuning into sound masking technology

Decentralized sound masking
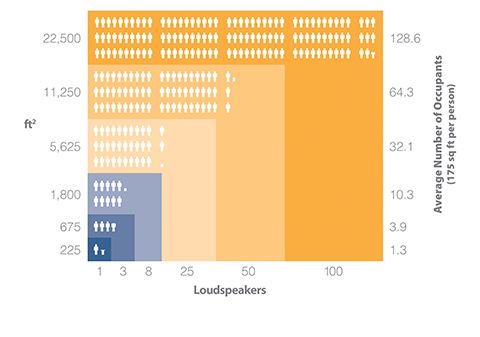
Decentralized architecture emerged in the mid-1970s to address the problem of large zone size. Rather than place sound generation, volume, and frequency control in a central location, the electronics required for these functions are integrated into ‘master’ loudspeakers, which are distributed throughout the facility—hence the ‘decentralized’ name.
Each ‘master’ is connected to up to two ‘satellite’ loudspeakers, which repeat its settings. Therefore,
a decentralized system’s zones are only one to three loudspeakers in size (i.e. 30 to 62 m2 [225 to 675 sf]). This distributed design inherently controls ‘phasing.’ Additionally, because each small zone offers fine volume control, local variations can be addressed, allowing more consistent and effective masking levels to be achieved across a facility. However, there are still limits to the adjustments that can be made with respect to frequency, which, in turn, impacts performance.
Further, a technician must make changes directly at each ‘master’ loudspeaker, using either a screwdriver (i.e. with analog controls) or an infrared remote (i.e. with digital controls), making future adjustments challenging. It is advisable to measure performance and modify a sound masking system’s settings when changes are made to the physical characteristics of the space (e.g. furnishings, partitions, ceiling, flooring) or to occupancy (e.g. relocating a call center or human resource functions into an area formerly occupied by accounting staff). The likelihood these types of changes will occur during a sound masking system’s 10- to 20-year lifespan is almost certain. Therefore, a ‘set-it-and-forget-it’ approach is neither practical nor advised. Engineers had to develop a more practical way of adjusting the masking sound.
Networked sound masking
The first networked sound masking system was introduced more than a decade ago. The technology leverages the benefits of decentralized electronics, but networks the system’s components together throughout the facility—or across multiple facilities—to provide centralized control of all functions via a control panel and/or software. Changes can be made quickly following renovations, moving furniture or personnel, maintaining masking performance within the space without disrupting operations.
When designed with small zones of one to three loudspeakers offering fine volume (i.e. 0.5 dBA) and frequency (i.e. 1/3 octave) control, networked architecture can provide consistency in the overall masking volume not exceeding ±0.5 dBA. It also offers highly consistent masking spectrums, yielding much better tuning results than possible with previous architectures. Some networked sound masking systems can also be automatically tuned using a computer, which first measures the sound and then rapidly adjusts the masking output to match the specified curve.
Today, there are several different product offerings within the centralized, decentralized, and networked categories. Some vendors have also utilized a hybrid design, implementing a decentralized architecture in closed rooms (e.g. private offices) and a centralized architecture in the open plan. However, the centralized architecture presents significant tuning challenges within the open plan—an area where occupants rely on masking for speech privacy and noise control.
Updating performance standards
Sound masking is a critical design element for which there is not much room for error. Without a set of performance standards, the client may not achieve the expected level of speech privacy, noise control, and occupant comfort. An ASTM Subcommittee E33.02 on Speech Privacy (part of ASTM Committee E33 on Building and Environmental Acoustics) is currently working on such a standard: WK47433, Performance Specification of Electronic Sound Masking When Used in Building Spaces. It is also in the process of updating:
- ASTM E1130, Test Method for Objective Measurement of Speech Privacy in Open-plan Spaces Using Articulation Index;
- ASTM E1374, Guide for Open Office Acoustics and Applicable ASTM Standards;
- ASTM E1573, Test Method for Evaluating Masking Sound in Open Offices Using A-weighted and One-Third Octave Band Sound Pressure Levels; and
- ASTM E2638, Test Method for Objective Measurement of the Speech Privacy Provided by a Closed Room.
In the meantime, a minimum performance guideline is to require the masking sound to be measured in each 90-m2 (1000-sf) open area and each closed room, at a height between 1.2 to 1.4 m (4 to 4.7 ft) from the floor (i.e. at ear height rather than directly below a loudspeaker). Some systems can adjust for smaller areas, but this is an acceptable baseline. Masking volume is typically set to between 40 and 48 dBA, and the results should be consistent within a range of ±0.5 dBA or less. The curve should be defined in third-octave bands and range from 100 to 5000 Hz (or as high as 10,000 Hz). It is a reasonable expectation to have ±2 dB variation in each frequency band.
The vendor should adjust the masking sound within the area as needs dictate, and provide a final report verifying the results. The report should indicate areas where the masking sound is outside tolerance and why (e.g. noise from mechanical equipment or HVAC).
Sign up for our weekly newsletter
Architectural materials and methods delivered right to your inbox
- CSI News and Notes: CSI Foundation’s construction camp; CSI spring exam; and more
- CSI News and Notes: CSI’s credentials; CSI conference theme; and more
- To be specific – CSI supports young AECO professionals
- CSI News and Notes: CSI’s foundation scholarships, national conference, and Crosswalk
- CSI News and Notes: AI’s impact; CSI 2024 conference, and more
Products






Read the Latest Issue

